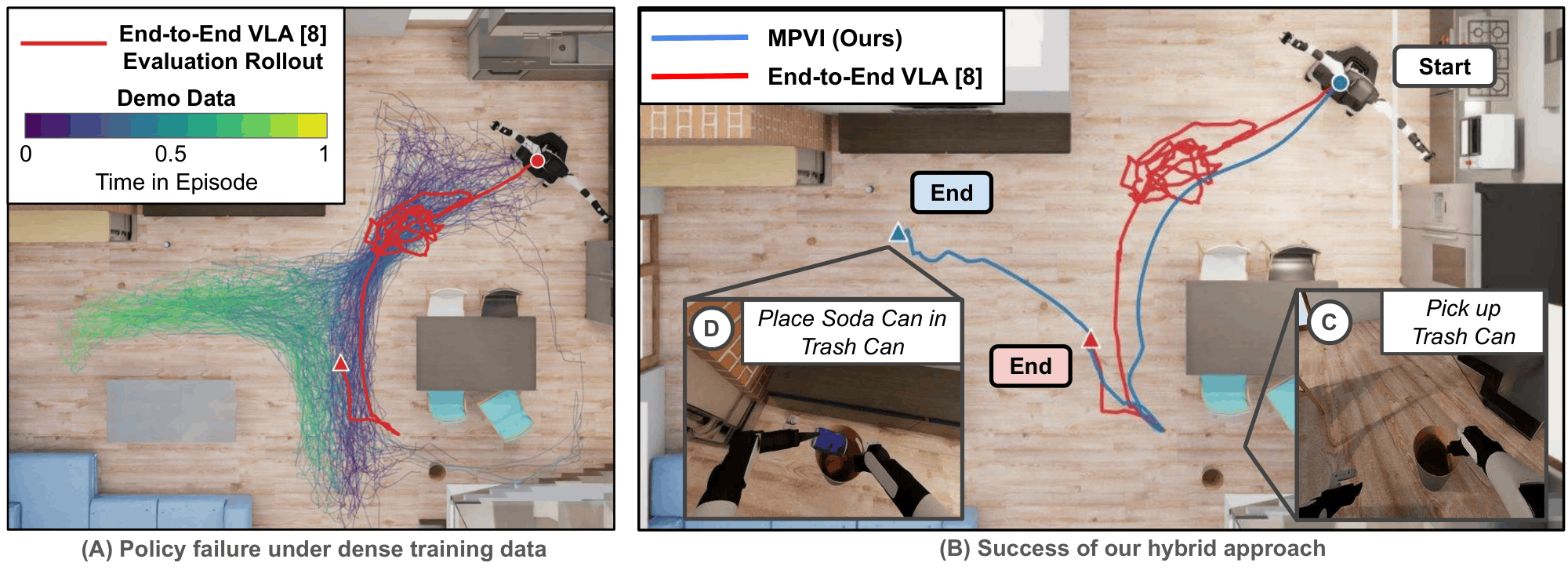
Vision-Language-Action (VLA) models have shown remarkable progress for mobile manipulation, but their performance on long-horizon tasks remains poor. These tasks are especially challenging because (1) progress toward high-level goals must be maintained across extended sequences of spatially distributed subtasks, and (2) early execution errors compound rapidly over the task horizon. These challenges persist despite finetuning on large human teleoperated mobile manipulation data, indicating that more data alone may not resolve the problem. To address these challenges, we propose MPVI: Motion Planner / VLA Interleaving, a framework that integrates model-based motion planning with VLAs to improve robustness without further training. The proposed integration enables localization and navigation to distant or occluded target objects through cluttered scenes using open-vocabulary object detection, frontier exploration and motion planning. However, such integration is non-trivial, requiring reliable switching between modules; we show one way forward via VLM-based completion checking with proprioceptive triggers. We evaluate our approach on the BEHAVIOR-1K benchmark and demonstrate 109% improvement in task progress over a top end-to-end VLA baseline.